



Prompting auf Steroiden - Wie RAG eure KI aufschlaut.
Was ihr in der KI nicht findet, findet ihr über euer RAG-System.
Willkommen bei Tech und Legal!
Heute wird es darum gehen, wie wir KI noch schlauer werden lassen und Wissen so aufbereiten, dass es schnell und effektiv abgerufen werden kann. Sollte es dir manchmal zu technisch werden, dann überspring gerne die Absätze. Ich habe den Artikel so geschrieben, dass dir kein Kontext verloren geht.

Viel Spaß beim Lesen und wenn es dir gefällt, dann leite den Artikel gerne weiter.

Einführung
Wenn Unternehmen und Kanzleien über die Einführung von KI-Systemen nachdenken, dann dreht sich dies fast immer darum, die eigenen Informationen besser aufzubereiten, Mehrwerte aus den eigenen Daten zu ziehen und allen Personen einen kleinen Rechercheassistenten an die Seite zu stellen.
Leider können "einfache" KI einem Großteil dieser Anforderungen nicht genügen. Eine textverarbeitendes KI-Modell (LLM) ist keine allwissende Datenbank, kann nicht einfach alle Daten eines Unternehmens in sich "aufnehmen" und kann nicht mal gut recherchieren. Da fragt man sich doch gleich, wozu eigentlich das Ganze dann.🤷🏻♂️
Doch gebt eure Hoffnung nicht auf, denn es gibt eine Lösung dafür. Anstatt die KI "direkt" zu fragen könnt ihr sie auch eure eigenen Dokumenten befragen lassen. Das hierfür notwendige System nennt sich RAG (Retrieval-Augmented Generation) [etwas holprig übersetzt "Abrufverstärkte Erzeugung"] und was euch jetzt noch mehr von den Socken hauen wird: Heute wird in meinem Newsletter genau darum gehen.🫢
Was ist RAG und wie funktioniert es?
Als RAG werden Systeme (AI-Frameworks) bezeichnet, die es einer KI ermöglichen, Informationen aus einer oder mehreren Quellen (meist Dokumente) zu verarbeiten, um die eigenen Antworten mit aktuellen und passenden Informationen zu erweitern.
Das bedeutet, dass bei einem Anfrage an den KI-Chatbot dieser nicht einfach "direkt" antwortet, sondern unter Hinzunahme weiterer Informationen die Antwort aufwertet. Hierbei werden Daten nicht einfach in das Kontextfeld gegeben, sondern sind nach einem gewissen System vorstrukturiert, so dass die KI bestmöglich die entsprechenden Informationen abrufen und verarbeiten kann. Es handelt sich somit nicht um eine einfache Suche in einem Dateisystem, die sich meist als sehr fehleranfällig und langsam herausstellt.
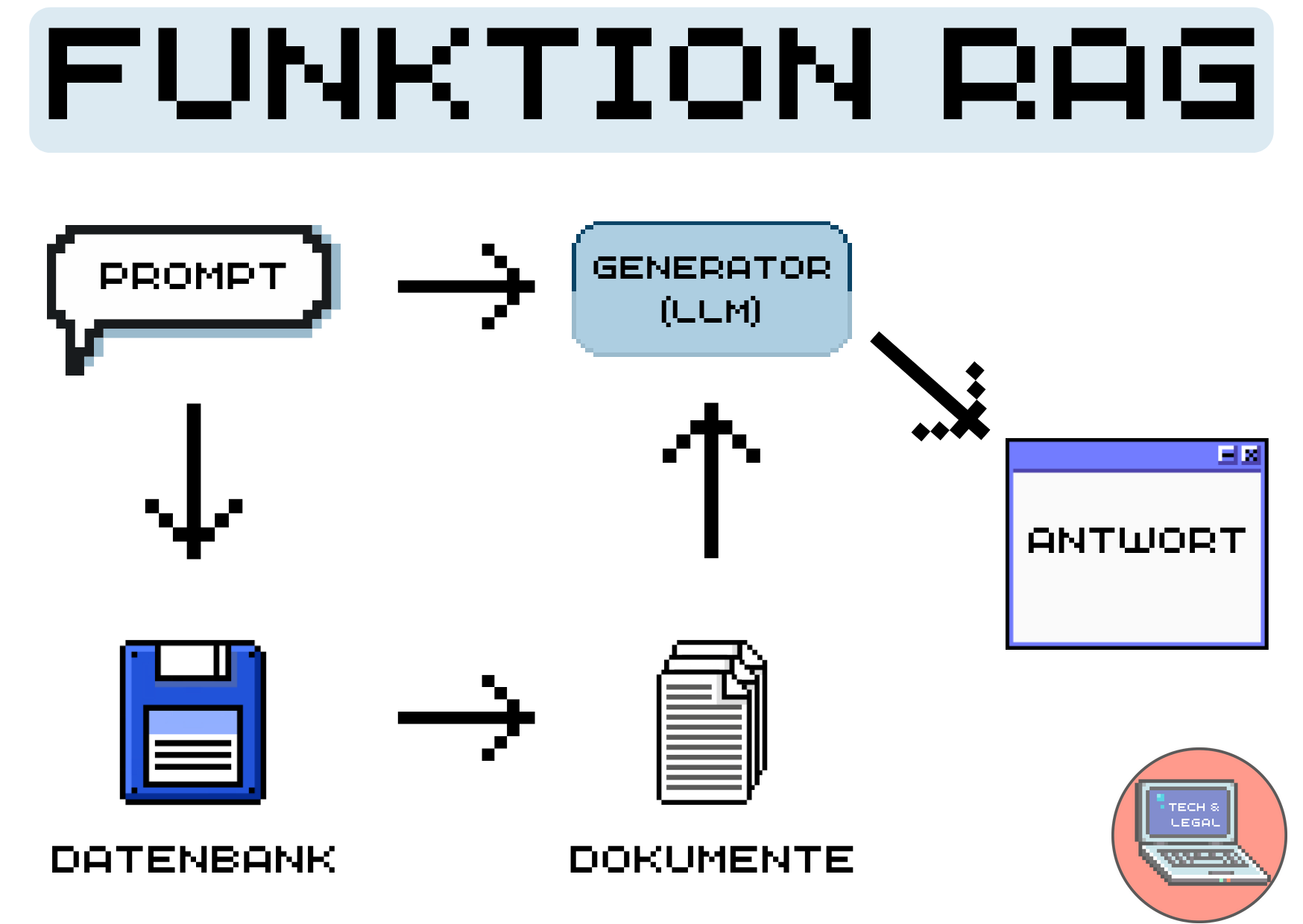
Das System arbeitet somit nach dem bekannten Prinzip "Man muss nicht alles wissen, aber wissen wo es steht". Sinn hinter dem System ist es, dass nun der KI-Chatbot mithilfe der eigenen Daten, welche aktuell gehalten werden können, konkrete Antworten geben kann. Das könnten dann bspw. in einem Unternehmen Daten zu Abläufen, Richtlinien oder dem operativen Geschäft sein. Die Mitarbeitenden können dann im Alltag schnelle Antworten zu ihren Fragen finden.
Deep Dive RAG - Wie funktioniert das technisch?
Jetzt wird es etwas technischer. Du solltest weiterlesen, wenn dich interessiert, wie du RAG bei dir einsetzen könntest.
Wie der Name schon sagt, besteht der Ablauf von RAG aus zwei Phasen. Die Abrufphase ("Retrieval") und die Texterstellungsphase ("Generation"). In der ersten Phase wird nach passenden Textstücken in den verbundenen Daten gesucht und in der zweiten Phase werden diese durch die LLM für den Prompt des Nutzers verarbeitet. Somit wird ein Prompt durch die entsprechenden Daten aufgewertet ("Augmented").
Die Vektordatenbank macht’s möglich
Grundlage für die Informationen ist eine Vektordatenbank, in welcher sich die abrufbaren Informationen befinden. Eine Vektordatenbank speichert Informationen nicht klassisch im Tabellenformat, sondern in einem "räumlichen" Format. Somit haben alle Informationen nicht nur eine "Zeile und eine Spalte", welche ihre Verbindung zu anderen Informationen bildet, sondern noch eine eine dritte Dimension. Diese erlaubt es Informationen "räumlich nah" zueinander abzuspeichern und damit ähnliche oder miteinander logisch verbundene Informationen mathematisch zu verbinden. Sehr vereinfach gesagt findet sich ein ähnliches Prinzip in den neuralen Netzwerken einer KI.
Den Effekt selber kennen wir alle von der Google Suchleiste, wo bereits bei der Eingabe weitere Vorschläge per (Auto Suggest) angeboten werden.
Es ist nun wenig überraschend, dass ein großer Teil der Entwicklungsarbeit eines RAGs genau in dieser Datenbank liegt.
Wie gelangen nun unsere Dokumente in diese Datenbank? Sie werden zunächst in kleine Stücke ("Chunks") aufgeteilt und dann erhalten diese einen mathematischen Wert, um diese dann mittels eines "Embeddings" in die Vektordatenbank aufzunehmen.
Erhält der KI-Chatbot nun eine Anfrage, wird das RAG diese Embeddings finden, wieder in einen Text übersetzen und es dem KI-Chatbot zur Verarbeitung bereitstellen.
Wie viel Aufwand macht so ein RAG?
Wenig überraschend ist der Aufwand immer umfangreicher als man denkt, was aber so ziemlich für jedes IT-Projekt gilt. Das System hat viele Hürden zu überwinden und spätestens hier wird es mehr als kompliziert. Man muss herausfinden,
welche Informationen (Dokumente) man nutzen kann und möchte,
wie man diese korrekt aufbereitet,
wie man sie teilt,
wie man die Beziehungen untereinander herstellt,
wie man die Informationen fortwährend weiterentwickelt
und welche Modelle man für die entsprechenden Teil nutzt usw.
Das alles erfordert Zeit und ein hohes Verständnis, nicht nur für die zu verarbeitenden Inhalte, sondern auch für die Architektur der einzelnen Software-Elemente. Die Erstellung eines RAG-Systems ist somit immer eine starke multidisziplinäre Aufgabe.
Der Entwicklungsprozess läuft zudem weniger gradlinig ab und gleicht mehr einem Experimentieren als einer klassischen Softwareentwicklung. Egal wie gut man vorbereitet ist, kann man im Vorfeld wenig abschätzen, wie die Dokumente bestmöglich in der Vektordatenbank liegen und was am Ende die KI daraus macht.
Das Prinzip beim Entwickeln ist "Ja, wir probieren mal aus und schauen mal wie weit wir kommen" und das hört man wohl nicht so gern von seinem Projektteam.
Warum nicht Finetuning?
Jetzt schreibe ich die ganze Zeit von RAG und wie kompliziert es ist. Warum versucht man es nicht einfach mit Finetuning?
Eine eigene LLM zu trainieren oder zu "finetunen", kann in wenigen bestimmten Fällen genau das Richtige sein. Gerade, wenn das Modell ganz bestimmte Aufgaben erfüllen soll und hierfür die eigenen Fähigkeiten, also das Verarbeiten von Texten, auf eine bestimmte Art von Texten spezialisiert sein soll, bspw. das Auslesen von Bescheiden. Finetuning wird daher auch bei RAG-Systemen genutzt, um die Fähigkeiten der LLM im Umgang mit den speziellen Daten zu erhöhen.
Finetuning hat jedoch auch klare Nachteile gegenüber RAG, man benötigt sehr gute Daten, hat keine aktuellen Informationen im Modell, keine Quellenangaben und kann sich nicht einmal sicher sein, ob das Ganze überhaupt ansatzweise funktioniert. Streng genommen vergleichen wir hier aber Äpfel mit Birnen.
Finetuning hat im Kern den Sinn die Verarbeitung selbst zu verändern, während RAG spezielle Informationen zur Verarbeitung bereitstellt.
Eine KI ist keine Datenbank und das kann auch ein Finetuning nicht verändern.
Tipps und Ideen
Solltet ihr euch entscheiden ein eigenes RAG-System erstellen zu wollen, dann kommt viel Arbeit auf euch zu, die sich jedoch sehr lohnen kann.
Möglicherweise macht es Sinn noch ein bisschen zu warten, welche Lösungen noch auf den Markt kommen. Aktuell wurde bspw. das RAG 2.0 von contextual.ai angekündigt, welches die einzelnen Elemente eines RAGs zu einem Ganzen verbinden möchte.
Aber egal welches Modell ihr wollt, ihr müsst immer bei euren eigenen Daten anfangen. Diese müssen qualitativ hochwertig sein. Bestenfalls habt ihr eine Datenstrategie und könnt euer RAG-System auch noch später mit Daten erweitern und aktuell halten.
Ich wünsche euch viel Erfolg und freue mich zu hören, wie es euch mit RAG so ergeht.
Wer noch mehr über RAG wissen soll, wird hier fündig.
Wer gleich mal selbst ein RAG mit Ollama bauen möchte, kann hier vorbeischauen.
Ich danke euch. 🙏

❤️ Sharing is Caring
Ausgabe teilen:
Newsletter teilen:
Newsletter abonnieren:

📊 Statistiken
Newsletter Nummer: 08
Empfangende Personen: 146 ↗️
Wörteranzahl Newsletter: 1.194
Beiträge: 1
Sätze: 81
Lesezeit: ca. 6 Minuten